나는 해당 프로젝트에서 데이터 엔지니어링을 맡았다.
내가 할 역할은 아래 WBS 중에서도 Data Processing 파트다. (데이터 엔지니어 꿈나무 🙋🏻♀️🙋🏻♀️)
⬇ 우리 팀의 WBS 링크
https://eng-sohee.tistory.com/50
따라서 오늘, 나는 가장 첫 작업인, 데이터 수집 요구사항 정의를 해보려 한다.
목차
수집 요구사항
수집 파이프라인
01. 수집 요구사항
- 요구사항 1: 정박 대기시간 예측 모델
- 요구사항 2: 실시간 선박 위치 좌표+대시보드화 (선박 검색)
- 요구사항 3: 해양 기상데이터 시각화
- 요구사항 4: 정박지 예약 현황 공유
- 요구사항 5:
위의 요구사항을 조금 더 자세히 구체화하여 작성해보았다. 매우 간단한 인터페이스 정의서라고 볼 수 있겠다.
| 요구사항 | 수집 구체화 |
| 요구사항1 | 수집 방법: Port-Mis 내 데이터 다운로드 or 크롤링 |
| 주기: 2주에 1회 (임시) 수기 저장 | |
| 데이터 출처: Port-Mis 항만시설-시설사용허가현황 https://new.portmis.go.kr/portmis/websquare/websquare.jsp?w2xPath=/portmis/w2/main/index.xml&page=/portmis/w2/cm/sys/UI-PM-MT-001-021.xml&menuId=0045&menuCd=M4735&menuNm=%BB%E7%C0%CC%C6%AE%B8%CA |
|
| 데이터 형태: xlsx | |
| 요구사항2 | 수집 방법: 실시간 선박 위치 API 데이터를 수집, 기준데이터 저장 |
| 주기: API의 경우 2분 단위 수집 주기: 마스터 데이터의 경우, (변경 될 가능성 있으므로) 한 달 단위 재수집 |
|
| 데이터 출처: API - 마린트래픽 유료 API https://www.marinetraffic.com/ 데이터 출처: 마스터 - 공공데이터 관할지역별 선박정보 https://www.data.go.kr/data/15044300/fileData.do |
|
| 데이터 형태: API의 경우 csv, xml, json 중 택1 & 마스터데이터의 경우 csv | |
| 요구사항3 | 수집방법: 실시간 해양기상관측자료의 API 데이터를 수집 |
| 주기: (전화문의 결과) 5분 | |
| 데이터 출처: 국립해양측위정보원 오픈 API https://marineweather.nmpnt.go.kr/serviceReq/serviceOpenApiIntro.do | |
| 데이터 형태: json | |
| 요구사항4 (논의 필요) | 수집방법: 정박지 예약 및 사용 현황, 사용 현황 데이터를 실시간 크롤링하여 시각화 |
| 주기: 추가 논의 필요 | |
| 데이터 출처: Port-Mis 항만시설-시설사용허가현황 https://new.portmis.go.kr/portmis/websquare/websquare.jsp?w2xPath=/portmis/w2/main/index.xml&page=/portmis/w2/cm/sys/UI-PM-MT-001-021.xml&menuId=0045&menuCd=M4735&menuNm=%BB%E7%C0%CC%C6%AE%B8%CA |
|
| 데이터 형태: xlsx 이지만, 크롤링의 경우 달라질 수 있음 (논의 필요) | |
| 요구사항5 (논의 필요) | 수집방법: 부두 상태 현황을 각 항만공사 사이트에서 실시간 크롤링하여 시각화 |
| 주기: 10분 단위로 수집 (추가 논의에 따라 변동 가능) | |
| 데이터 출처: 울산항만공사 재난안전 사이트 https://www.upa.or.kr/safe/pub/main/index.do | |
| 데이터 형태: 크롤링 필요 | |
| 특이사항: 서비스 적용될 항만의 범위 (전체 항만의 현황 or 울산항만의 현황)에 대한 추가 논의 필요 (사유: 부두 현황 대시보드는 현재 울산항만공사만 제공) |
02. 수집 파이프라인
지금 어떻게 할지 지금도 조금은 고민되지만, 혼자 고민한 바로는 아래와 같다.
1. 우리 프로젝트의 데이터 양은 그렇게 많지 않기 때문에, 2개의 스토리지만 사용한다.
배치 데이터와 실시간 데이터(나는 이 프로젝트에서 시간 단위 미만 데이터는 모두 실시간 데이터로 지칭할 것이다.)로 나눠 데이터를 저장해서 사용할 것이다.
2. 요구사항 1과 요구사항 4는 같은 데이터지만 용도가 다르다.
요구사항 1은 배치 수집 형태로, 추후 분석을 위해 수집을 하는 것이라 2주 1회 수기로 xlsx 파일을 다운로드하여 저장해도 된다. 그것이 더 경제적이기 때문이다.
하지만 요구사항 4는, 홈페이지에 접속할 때마다 실시간 데이터를 집계해 보여줘야 한다.

이를 해결하기 위한 방법은 두 방법으로 나뉘겠다는 생각이 들었다.
| 방법1 | 방법2 | |
| 설명 | 한 데이터 소스지만, 각각 필요한 일정에 따라 DB에 저장(2주 간격)하거나, 웹에 시각화(초당)하는 작업 수행 | 데이터 소스에서 초 단위로 DB에 저장해, 저장된 데이터에서 웹사이트로 시각화 |
| 단점 | 1. 다소 효율적이지 못함 2. 시각화 창 로드 시 약간의 버퍼링 발생 우려 |
1. DB 무결성 확보 불가능 2. 서버에서 오류가 나면, 오류 및 중복 발생 가능성 높음 - 중복은 높은 비용의 오퍼레이션임 3. 중간 테이블 반드시 필요하며, DB에서 일자 별 테이블 파티셔닝에 의한 치환 작업이 필요할 것으로 보임 |
| 장점 | DB의 무결성 및 안정화 확보 가능 |
이중일을 하지 않아도 되므로 효율적임 |
나는, 프로젝트의 전체적인 효율을 위해 어느 정도의 중복 작업을 허용키로 했다.
따라서 방법 1을 택할 것이다.
🔥 방법 1을 택한 이유?
나는 우리 프로젝트에는 방법 1이 더 적합하다고 봤다. 의사결정에 대한 이유는 아래와 같다.
1. 서비스 결과물의 방향성
우리 서비스 결과물은, 데이터 시각화도 중요하지만 예측 알고리즘 기반 의사결정 도모가 더욱 중요한 목적이기 때문에, 데이터베이스 무결성을 극대화하는 방법을 택하는 것이 좋겠다고 보았다. (데이터가 매우 많으면 2번을 택해도 좋지만, 앞서 말한 대로 우리는 데이터가 그리 많지 않아, 조금의 오류도 알고리즘 구현에 있어 큰 치명타가 될 수 있다고 보았다.)
2. 중복을 제거하는 것은 오프셋이나 고유 ID를 이용하여 해결해야 하는 높은 비용의 오퍼레이션인데, 방법 2에서 중복은 불가피하다. 방법 2의 문제를 해결하는 데에 드는 공수보다, 방법 1에서 들어가는 공수가 조금 더 경제적이라고 보았다.
대신, 방법 1의 한계점을 극복하기 위해 중간에 임시 스토리지를 집어넣어, 시각화 창 로딩 최적화를 구현하고자 한다.
3. 스토리지는 NoSQL을 사용한다.
HDFS, HBase를 사용할지, NoSQL을 사용할지 고민했는데, 아무래도 요즘 많이 떠오른다는 조합인 NoSQL을 분산 스토리지처럼 사용하는 방법을 써보기로 했다. 그중에서도, 점점 많은 데이터를 저장해야 하므로 확장성이 뛰어난 MongoDB를 사용할 것이다.
NoSQL에 대한 설명은 이전 포스팅을 참고하면 된다.
⬇ 이전 포스팅 링크
01. 빅데이터를 지탱하는 기술 - 빅데이터의 기초 지식
나는 데이터엔지니어를 희망한다. 데이터엔지니어가 몹!시! 되고 싶은 사람으로서, '빅데이터를 지탱하는 기술'을 수차례 읽었던 것 같다. 머릿속에 있는 정보를 작성해 온전히 내 것으로 정보
eng-sohee.tistory.com
🔥 데이터베이스를 MongoDB로 선택한 이유?
높은 확장성이 주된 이유다. 부수적 이유는 아래와 같다.
물론 우리 데이터 중 많은 부분이 임시 저장 데이터이므로 Redis를 활용하면 더욱 적합하겠지만, 우선 우리 팀원들도 익숙한 DB를 쓰기로 했다. 중단기 프로젝트기 때문에, 학습에 들어가는 비용(시간도 비용으로 간주)이 너무 크다면, 조금은 느리더라도 전체적 관점에서 더 효율적인 방법을 쓰는 것이 맞다고 판단했기 때문이다. (여기서 정 느리다고 한다면 Redis로 옮기는 방법을 차선책으로 두긴 했다.)
그리고, AWS Lambda를 쓸 것이라서 DynamoDB를 쓰면 연계가 더 잘된다는 점 때문에 DynamoDB를 쓸까도 고민했지만, 아래 게시물을 참고해 MongoDB를 쓰기로 했다.
DynamoDB 대신 MongoDB를 써야 하는 7가지 이유
MongoDB를 주로 쓰다가 AWS 환경을 염두에 두게되면서 DynamoDB를 알아보던 중 눈에 들어온 글이 있어 대충 번역해서 공유해봅니다. 출처 : http://www.masonzhang.com/2013/08/7-reasons-you-should-use-mongod..
kuimoani.tistory.com
4. 정기적 수집을 위해 어떤 수집 아키텍처를 쓸 것인가?
이것 때문에 정말 몇 날 며칠을 고민했다. 진짜 정말 엄청 찾아봤다.. 하둡을 쓸지, AWS 기반 빅데이터 수집을 할지, 구글 빅쿼리와 GCP를 이용할지... 엘라스틱서치 강의까지 듣고... 뜨흑.
뭐가 더 비용적인 부분에서 경제적이고 뭐가 더 우리 프로젝트에 잘 맞을지... 고민하고, 주위 물어볼 수 있는 분들(온라인으로 댓글 달고, 질문하고...)께 질문을 하며 고민 또 고민했다.
우선 결론부터 말하면, (수집의 경우) AWS Lambda를 이용해 API 데이터 수집+크롤링을 진행할 것이며,
이를 NoSQL(데이터 소스 스토리지로 사용) 중 MongoDB를 이용할 것이다. CSV 파일로 월별 저장이 가능한 데이터들은 수기로 MongoDB에 적재할 것이다. (데이터 수집은 자동화될수록 공수가 줄어 경제적이므로, 이 또한 자동화할 방법을 계속 고민해보고 있다.) 이때, 중간 스토리지를 만들되 치환하는 방식을 적용할 것이고, 테이블 파티셔닝을 통해 데이터의 무결성을 극대화할 것이다.
4-1. 왜 하둡이 아닌 방법을 선택했는가?
평소 온라인 강의를 듣고 있는 강좌에 선생님께 질문을 드렸는데,
질문에서도 하둡보다는 스크래파이와 같은 스크래핑 기술을 더 추천해주셨다. (아무래도 fluentd나 flume은 로그 데이터 수집에 더 적합하기 때문이다.)
4-2. 왜 AWS Lambda를 선택했는가?
서버 없이도 주기적으로 데이터를 끌어오는 코드를 구현해줘야 하기 때문이다.
물론 그냥 API를 서버에 연결해서 서버 켜질 때마다 API를 끌어와도 되긴 한다. 그런데 이 방법은 매우 느렸다.
(전주시 데이터 분석 공모전을 준비하며 느낀 경험담...)
따라서 중간 데이터 마트를 만들어, 실시간으로 데이터가 시각화될 때 부하를 줄여 속도를 높일 것이기 때문에. 서버가 없이도 스크래핑 코드가 돌아가는 Lambda를 활용하고자 한다.
이것저것 정말 많은 구글링을 했지만, 가장 도움이 됐던 세 가지의 링크를 걸어두도록 하겠다.
https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/services-cloudwatchevents-expressions.html
Rate 또는 Cron을 사용한 예약 표현식 - AWS Lambda
Rate 또는 Cron을 사용한 예약 표현식 AWS Lambda는 분당 최대 한 번의 빈도로 표준 rate 표현식과 cron 표현식을 지원합니다. CloudWatch 이벤트 rate 표현식은 다음 형식을 갖습니다. rate(Value Unit) Value는 양
docs.aws.amazon.com
AWS Lambda 주기적으로 자동실행하게하기
※ Lambda 와 DynamoDB의 기본적인 사용법은 생략했습니다. 이번에 주기적으로 람다함수를 자동실행하게 하는방법을 찾던도중 CloudWatch Events 를 이용하면 람다를 자동으로 실행하게할수있다는것을
dulki.tistory.com
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=nan17a&logNo=222083347120
[AWS] lambda를 특정 시간에 자동 실행하기(cron 배치)
만들어진 lambda함수를 특정 시간에 실행하고 할때 적용한 방법이다. 1. EventBridge(CloudWatch Even...
blog.naver.com
이 글의 내용을 개략적으로 그림으로 표현한다면 아래와 같을 것이다.
우선 처리 프로세스는, 수집이 끝난 뒤 더 자세히 고민해보아야 할 것 같다.
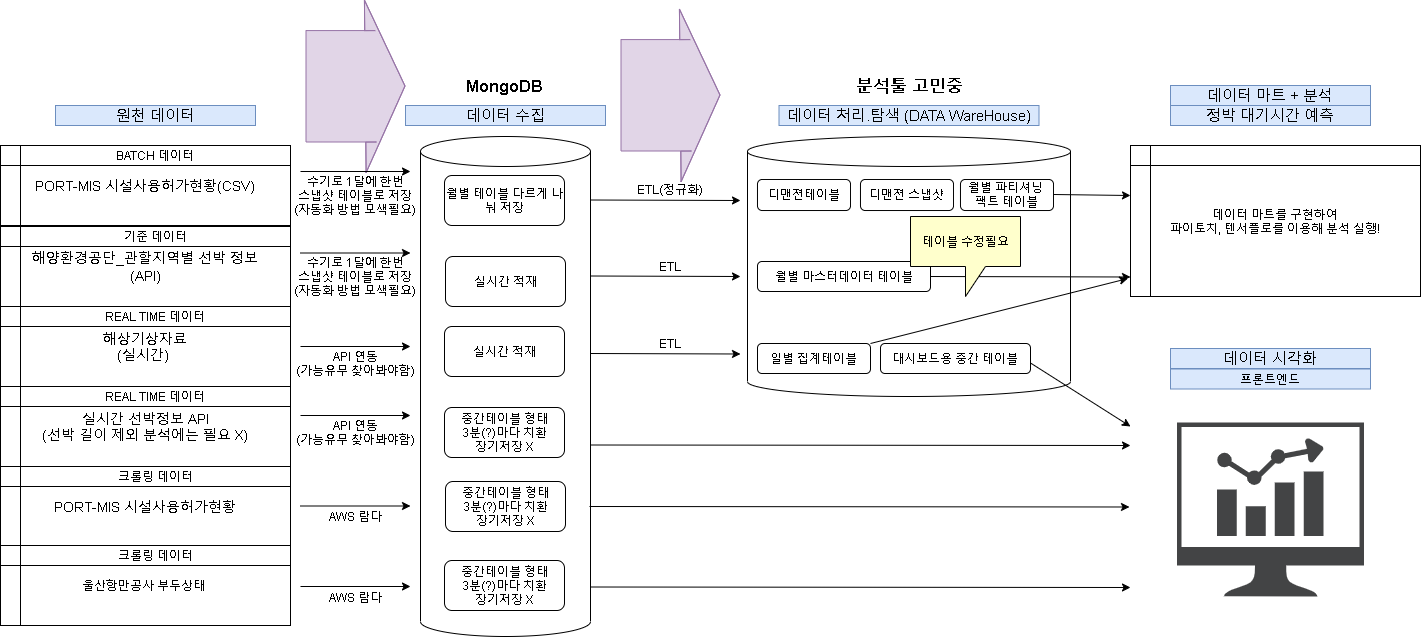
별 것 안 한 것 같지만, 이를 고민하고 다른 툴과 비교해가면서 결정하는 게 생각보다 무척 골치 아팠다.
물론 지금 내가 한 고민 끝 결과도, 누군가에겐 단순할 수도 못마땅할 수도 있다. 최적의 결과가 아닐 수 있다(=더 효율적 방법이 어딘가에 존재한다)는 생각에 현업에서 배우고 싶은 마음이 굴뚝같은 요즘이다 ㅠㅠ
그럼 수집 아키텍처 설계는 여기서 끝!
'개인(팀) 프로젝트 > 해상물류 통합 데이터 플랫폼 프로젝트' 카테고리의 다른 글
| 데이터베이스에 csv 파일 업로드 시 에러(value too long for type character) 해결 (0) | 2021.08.01 |
|---|---|
| 09. Selenium - 동적 사이트 테이블 Crawling : 오류 해결 (3) | 2021.07.13 |
| 08. PSST 기반 사업계획서 작성 방법 (0) | 2021.07.01 |
| 07. Selenium - 동적 사이트 테이블 Crawling (0) | 2021.06.28 |
| 01. 문제 및 요구사항 정의, 와이어 프레임 설계 (0) | 2021.06.01 |