목차
플럼이란
플럼 설치
카프카란
카프카 설치
01. 플럼이란
이번 프로젝트에서는, 빅데이터 수집을 위해 플럼을 사용한다.
플럼은 DB, API, 파일 등으로부터의 로그 데이터 수집을 지원하는 소프트웨어다.
사실 요즘은 플럼이 오래된 기능이라고 잘 쓰이지 않고, 이를 대체하여 현업에선 fluentd 등을 더 많이 찾는다고 한다.
2-1. 플럼의 구조
플럼은 크게 5가지로 구성되어 있다.
| 플럼의 주요 구성요소 | |
| 소스(Source) | 데이터 소스 파일로부터 데이터 수집 |
| 싱크(Sink) | 채널로부터 데이터 전달받아 적재 장소로 전달 HDFS, ElasticSearch, Hive 등을 제공 |
| 채널(Channel) | 소스와 싱크를 연결 |
| 인터셉터(Interceptor) | 수집 중 데이터 가공을 원할 때 선택적으로 사용 |
| 에이전트(Agent) | 하나의 파이프라인 세트(소스,인터셉트,채널,싱크)를 의미 |
일반적인 파이프라인은,
소스 - (인터셉트) - 채널 - 싱크
로 구성되어있으며, 싱크를 여러 개로 복사해 전달할 수도 있고 소스를 여러 개로 둘 수도 있다. 비즈니스 로직에 따라 복합적인 처리가 가능하다.
02. 플럼 설치
클라우데라 매니저를 활용하면 손쉽게 설치가 가능하다.
앞서 만들어두었던 Cluster 1에 플럼 서비스를 추가해보겠다.

그 후, 역할 호스트 (즉 설치할 서버명)는 Server02에 설치하도록 하겠다.
java heap 등 파라미터 값을 원하는 대로 조절해주면, 설치는 끝이다. 클라우데라 매니저를 쓰면 매우 간편하다!
03. 카프카란
카프카(Kafka)는 리얼타임 데이터를 수집할 때, 초단위로 계속 가져오는 것이 아니라 한 번에 모아서 가지고 올 수 있도록 하는 기능이다.
🔥 카프카가 왜 필요할까?
중간에 일시적 서버 오류가 날 때, 휘발되는 실시간 로그 데이터들은 DB에 집계될 수 없다. 하지만 카프카가 있으면 모아서 전송하고 어느 정도 임시 저장을 하기 때문에 위와 같은 오류에 대처할 수 있다. 그리고 모아서 한 번에 전송해서, 성능이 떨어지지 않는다.
3-1. 카프카의 구조
카프카는 크게 4가지의 구조로 이루어져 있다.
| 카프카의 주요 구성요소 | |
| 브로커(Brocker) | Topic이 생성되는 물리적 서버 |
| 토픽(Topic) | 데이터의 임시 저장소 |
| 프로바이더(Provider) | 토픽으로 데이터를 전달. 애플리케이션에서 카프카 라이브러리 이용해 구현 |
| 컨슈머(Consumer) | 토픽에서 데이터를 수신. 애플리케이션에서 카프카 라이브러리 이용해 구현 |
일반적인 파이프라인은,
프로바이더 - 브로커 내 토픽 - 컨슈머
로 이뤄져 있다. 이것 또한 플럼과 마찬가지로, 여러 개의 프로바이더에서 여러 개의 컨슈머로 전달할 수 있다. 그리고 여러 개의 중개인을 둘 수도(멀티 중개인과 멀티 노드), 여러 개의 토픽을 둘 수도 있다. 이것 또한 비즈니스 로직에 따라 다르다.
04. 카프카 설치
카프카 설치도 플럼과 동일하게, 클라우데라 매니저에서 선택해 설치할 수 있다.
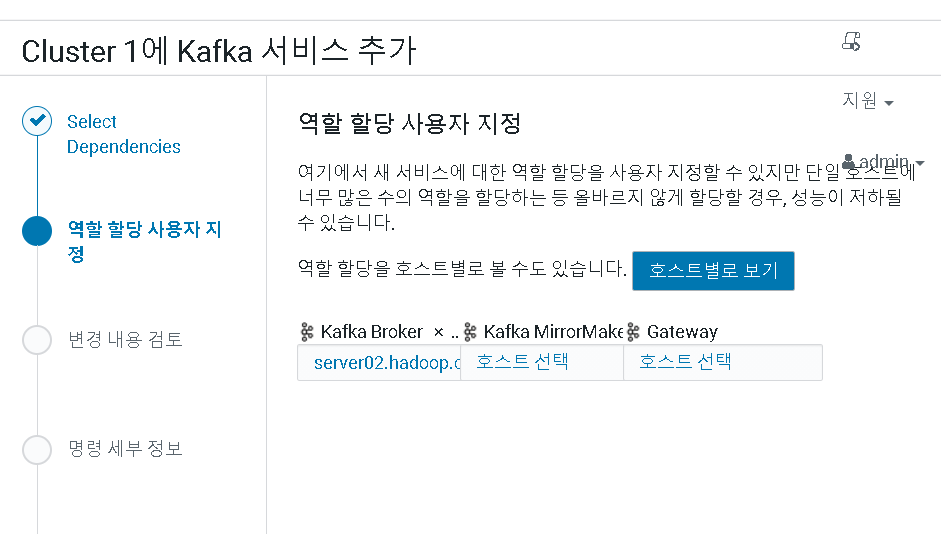
이때, 역할 할당 사용자 지정은 Brocker만 Server02로 지정해준다. 그후 저장을 하면 된다!
설치가 다 완료되면, 원하는 파라미터값을 구성에서 조정해주면 된다.
이번 프로젝트에서는 카프카가 데이터를 보관하는 기간을 7일에서 15분으로 줄였다. (저장공간 이슈로 인해)
이렇게 하면 카프카와 플럼 설치는 끝이다. 이제 실습을 통해, 카프카와 플럼이 잘 설치되었는지 확인해보자.
다음 포스팅에서는, 플럼과 카프카를 실행해 볼 것이다! (드디어!)
'개인(팀) 프로젝트 > 기타 프로젝트 & 활동' 카테고리의 다른 글
| 07. 플럼(flume)을 통한 빅데이터 수집 (0) | 2021.06.17 |
|---|---|
| 06. 플럼과 카프카 기능 구현 방법 (0) | 2021.06.17 |
| 04-1. 클라우데라 매니저 HDFS 에러 해결 (0) | 2021.06.16 |
| 04. 수집 요구사항 정의 + HDFS, 주키퍼 설치 및 실행 (0) | 2021.06.16 |
| 03. 로그 시뮬레이터 설치 (0) | 2021.06.15 |