안녕하세요 한소희입니다. 공부를 통해 배운 내용을 작성하고 있습니다. 혹여 해당 포스팅에서 잘못된 부분이 있을 경우, 알려주시면 빠르게 수정 조치하도록 하겠습니다. 감사합니다.
데이터허브 구축기를 작성해 보고자 한다.
목차는 아래와 같으며, 포스팅이 생각보다 길어져서, 몇 개의 글로 나누어 포스팅할 예정이다.
첫 번째 포스팅에서는 데이터허브가 무엇인지 알아보았고
두 번째 포스팅에서는 데이터허브 구축 시 ElasticSearch 구축~연동 과정을 다루었다.
이번 포스팅 또한 두 번째 포스팅에 이어서, 데이터 허브 구축 과정을 포스팅할 생각이다. Confluent Kafka 연동 및 DB 연동, Datahub 구축 과정을 회고하며 포스팅을 마무리할 계획이다.
목차
01. Datahub
02. Datahub 용어 정리
03. Datahub 구축 (2/2)
04. Datahub를 구축하며 느낀 점, 마무리
03-4. Datahub 설치 - 3단계: Kafka 연동
Confluent Kafka는 prerequisite 에 포함된 Kafka와 다르게, Datahub 연동 시 고려해야 할 부분들이 존재한다.
(1) 추가적인 변수 값들을 필요로 한다거나,
(2) Helm에서 다뤄지는 datahub-actions 기본 이미지를 그대로 적용하면 Kafka가 정상 연동되지 않기 때문에, datahub-actions 에서 Confluent Kafka 관련 환경변수를 로드할 수 있도록, datahub-actions 이미지를 수동 빌드하는 과정이 필요하다.
따라서 관련 작업 시 알아야 할 부분을 중점으로 포스팅해보도록 하겠다.
1. Schema Registry 설정
datahub values.yaml에 들어가야 할 코드 예시는 아래와 같다.
schemaregistry:
type: KAFKA
url: "https://{schema_registry_url}"
2. springKafkaConfigurationOverrides value 기입
Confluent Kakfa 관련 설정 값들은 default values.yaml에 비명시되어 있으나, 공식 문서에 충분히 설명 되어 있다.
공식 문서 링크는 아래와 같다.
https://datahubproject.io/docs/0.11.0/deploy/confluent-cloud
Integrating with Confluent Cloud | DataHub
DataHub provides the ability to easily leverage Confluent Cloud as your Kafka provider. To do so, you'll need to configure DataHub to talk to a broker and schema registry hosted by Confluent.
datahubproject.io
링크 내 글과 같이, sasl.username, sasl.password를 이용해 Confluent Kafka 연결을 시도할 경우에는 아래 예시 코드와 같이 셋팅하면 잘 접속되는 부분을 확인할 수 있었다.
** 이때 secret을 동일 네임스페이스에 생성하여, credentialsAndCertsSecrets 에 내부 값을 넣어주면 보안 설정이 가능하다.
** 이때 basic.auth.credentials.source 값을 명시하자! (나의 경우 sasl.username, sasl.password 을 이용해 접속을 하였으므로 USER_INFO 설정을 명시해 주었다.)
credentialsAndCertsSecrets:
name: {secret-name}
secureEnv:
sasl.jaas.config: sasl_jaas_config
basic.auth.user.info: basic_auth_user_info
sasl.username: sasl_username
sasl.password: sasl_password
springKafkaConfigurationOverrides:
kafkastore.security.protocol: SASL_SSL
security.protocol: {}
sasl.mechanism: {}
sasl.kerberos.service_name: kafka
basic.auth.credentials.source: USER_INFO
client.dns.lookup: use_all_dns_ips
session.timeout.ms: {}
retry.backoff.ms: {}
3. acryl-datahub-actions Docker 이미지 별도 배포 (v.23.11.22)
보통 다른 변수 설정값들은 helm으로 묶여 있어, dafault 이미지에서도 각자 필요한 variables이 각자의 애플리케이션으로 잘 인입이 되는데,
acryl-datahub-actions 만큼은 Default 이미지에서 confluent kafka를 연동하기 위해 내부에서 필요한 values 일부가 누락된다. (v.23.11.22 기준, 이후 업데이트 되었을 수 있습니다.)
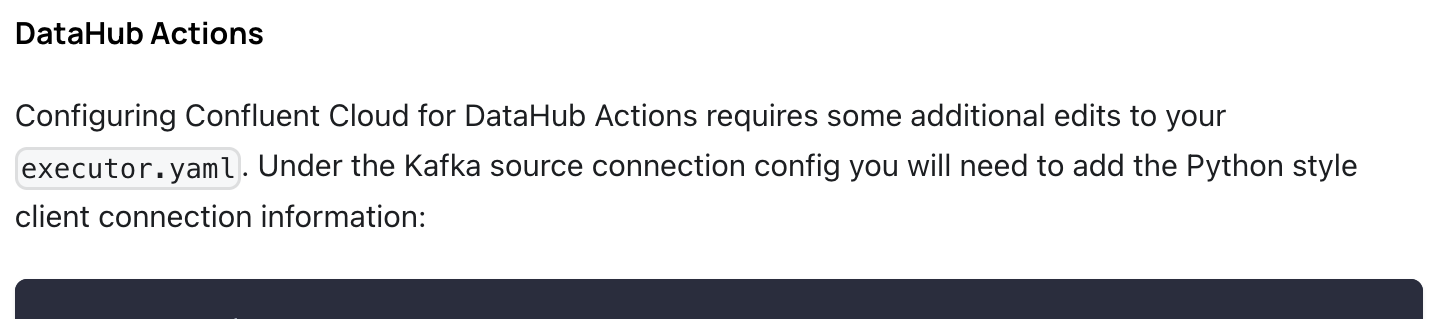
따라서 docker/config/executor.yaml 파일 내 consumer_config을 추가로 세팅해준 뒤 docker image를 생성/빌드하여, helm 차트 내 acryl-datahub-actions iamge 설정값을 변경해주어야 한다.
그렇지 않으면, KafkaSetup Job은 정상적으로 실행이 되었음에도 Datahub 서비스가 정상적으로 띄워지지 않음과 동시에 아래와 같은 Kafka 관련 에러가 난다.
Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Unauthorized; error code: 401
장황하게 설명을 하였는데, 이를 단계로서 정리하자면 아래와 같다.
3-1. datahub-actions clone (link: https://github.com/acryldata/datahub-actions)
위 링크인 datahub-actions repo를 클론 한다.
3-2. ./docker/config/executor.yaml 파일 내 consumer_config 항목 값 추가
예시 코드는 아래와 같다.
consumer_config:
security.protocol: ${KAFKA_PROPERTIES_SECURITY_PROTOCOL:-PLAINTEXT}
sasl.mechanism: ${KAFKA_PROPERTIES_SASL_MECHANISM:-PLAIN}
sasl.username: ${KAFKA_PROPERTIES_SASL_USERNAME}
sasl.password: ${KAFKA_PROPERTIES_SASL_PASSWORD}
schema_registry_config:
basic.auth.user.info: ${KAFKA_PROPERTIES_BASIC_AUTH_USER_INFO}
3-3. 변경된 폴더에 대해, docker image build & push
(나의 실행 환경은 GKE 이므로, GKE 환경으로 push 하는 예시 코드를 첨부하도록 하겠다.)
docker build --platform=linux/amd64 --no-cache -t datahub-actions -f docker/datahub-actions/Dockerfile .
docker tag {docker_image_id} asia.gcr.io/{project-id}/datahub-actions:{version}
docker push asia.gcr.io/{project-id}/datahub-actions:{version}
3-4. datahub values.yaml에 '3-3'에서 push 한 이미지로 변경
datahub-actions의 이미지를, 앞서 위 '3-3'에서 재 빌드한 이미지로 변경해 준다. 코드 예시는 아래와 같다.
acryl-datahub-actions:
enabled: true
image:
repository: asia.gcr.io/{project-id}/datahub-actions
tag: "{version}"
이 부분에 대해 설명되어 있는 공식문서 링크도 함께 첨부하도록 하겠다.
여담이지만, 한 문단이길래 이 부분을 간과했다가 원인을 파악하고 반성하는 시간을 가졌다. 역시 공식 문서는 꼼꼼히 읽어야 한다는 것을 또 새겼다.
여기서 잠깐, 환경변수가 각 pod에 어떻게 저장되어 있는지 확인하려면?
pod가 일종의 애플리케이션이므로, pod에 접속해서 환경변수를 체크하면 된다.
가령 datahub-gms pod에 접속한다고 가정한다면, 아래와 같이 실행할 수 있다.
# pod 접속
>> exec kubectl exec -i -t -n {NAMESPACE} {POD_NAME} -c datahub-gms -- sh -c "clear; (bash || ash || sh)"
# 환경변수 체크
>> export
03-5. Datahub 설치 - 4단계: DB 연동
이제 마지막으로 DB만 연동해 주면 굵직한 설정은 끝이 난다.
아래 예시 코드에서는, MySQL이 아닌 PostgreSQL(prerequisite 이 아닌, 외부 리소스)을 연결했다.
또한, password는 secret을 생성하여 적용하였다.
# mysqlSetupJob 비활성화
mysqlSetupJob:
enabled: false
...
# postgresqlSetupJob 활성화
postgresqlSetupJob:
enabled: true
...
# connection 정보 입력 (MySQL 주석, PostgreSQL 정보 입력)
global:
...
sql:
# datasource:
# host: "prerequisites-mysql:3306"
# hostForMysqlClient: "prerequisites-mysql"
# port: "3306"
# url: "jdbc:mysql://prerequisites-mysql:3306/datahub?verifyServerCertificate=false&useSSL=true&useUnicode=yes&characterEncoding=UTF-8&enabledTLSProtocols=TLSv1.2"
# driver: "com.mysql.cj.jdbc.Driver"
# username: "root"
# password:
# secretRef: mysql-secrets
# secretKey: mysql-root-password
# --------------OR----------------
# value: password
datasource:
host: "{host}:{port}"
hostForpostgresqlClient: "{host}"
port: "{port}"
url: "jdbc:postgresql://{host}:{port}/{db-name. default: datahub}"
driver: "org.postgresql.Driver"
username: "{username}"
password:
secretRef: {password-secret-name}
secretKey: {secret-key-name}
이후 서비스가 정상적으로 실행되는지 테스트한 후 ingress를 달아 주어 마무리를 하였다.
(ingress는 포스팅 영역을 벗어나는 것 같아, 추후 포스팅하겠다.)
04. Datahub를 구축하며 느낀 점, 마무리
최근 원티드에서 데이터 볼트 라는 AI 업무 생산성 로봇을 개발한 것을 알게 됐는데, 이 데이터 볼트 또한 '데이터 카탈로그의 학습'으로 데이터를 이해시켜 모델링을 했다고 한다.
우리도 이제 Datahub를 통해 사내 데이터 카탈로그 전체 수집 환경이 구축되었으니, 원티드의 '데이터 볼트'와 같은 다양한 시도를 해볼 수 있겠다는 생각도 들었고, 이 'Datahub'라는 서비스를 통해 누군가의 업무에 양질의 도움이 되었으면 하는 바람이다.
돌아보면, 우연한 계기로 데이터 디스커버리 플랫폼의 부재 및 필요성을 느꼈는데, 이러한 필요성에 대해 의견을 내보기도 하고, 의견을 내본 것을 넘어 직접 구축해 본 과정은 상당히 뜻깊고 감사한 시간이었다.
또한 블로그에 구축 과정에 대해 글을 쓰며, Datahub란 무엇인지부터 시작하여 Datahub 구축 과정에서 부딪혔던 부분을 중점으로 포스팅을 해보았는데,
이 과정을 담은 포스팅이, Datahub를 새로 구축하거나 & 운영 중인 엔지니어 분들께 도움이 된다면 더할 나위 없이 기쁠 것 같다는 생각이 들며, Datahub 구축기를 마치도록 하겠다.
'데이터 공부 > 빅데이터 & 하둡' 카테고리의 다른 글
| 데이터허브(Datahub) 구축기 - (2/3) ElasticSearch 구축 및 연동 과정 (45) | 2023.11.25 |
|---|---|
| 데이터허브(Datahub) 구축기 - (1/3) 데이터허브란, 데이터 허브 용어 살펴보기 (48) | 2023.11.22 |
| [책리뷰] 데이터 과학자 원칙 (0) | 2023.07.02 |
| 06. 빅데이터 분석 기반의 구축 (마지막 Chapter) (1) | 2023.06.18 |
| 04. Spark 간단히 살펴보기, 기능 둘러보기 (0) | 2021.07.15 |