목차
데이터셋 설명
분석 코드
01. 데이터셋 설명
데이터는 캐글에서 제공하는 고객 구매 데이터를 사용했다.
링크는 아래와 같다.
https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python
Mall Customer Segmentation Data
Market Basket Analysis
www.kaggle.com
해당 데이터의 경우, 고객이 특정 몰에서 구매한 데이터 200 raw로 구성돼 있다.
각 칼럼값은 총 4개이며, 컬럼은 아래와 같다.
- CustomerID (고객ID)
- Age (나이)
- Annual Income (k$) (연간 수입)
- Spending Score (1-100) (지출 지수)
02. 분석 코드
2-1. data frame 로드
필요한 라이브러리를 import 하고, read_csv를 이용해 데이터값을 불러왔다.
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import make_interp_spline, BSpline
df = pd.read_csv("/Mall_Customers.csv")
2-2. 데이터셋 확인
코드 살펴보기
# 데이터셋 확인
print('\n')
print(df.head(3))
print("\n-------------------------------------------------\n")
print(df.info())
print("\n-------------------------------------------------\n")
print(df.describe())
코드 실행 결과

코드 실행 결과는 위와 같다. 이를 통해 해당 데이터의 특징을 알 수 있는데, 가장 큰 특징을 정리하자면 아래와 같다.
- 4개의 컬럼 (CustomerID, Age, Annual Income (k$), Spending Score (1-100))
- 200 raw , all not null
- Gender 컬럼은 Object이며, 이외 Dtype은 int64
2-3. EDA (시각화)
데이터 전처리에 앞서, 어떤 기준으로 처리할 것인지를 보기 위해서 EDA가 정말 중요하다고 생각한다.
이 EDA를 통해 처리 방향이 달라지고, 이 처리 결과값에 따라 예측에도 참 많은 영향을 미친다. 즉, 이는 데이터 분석에서 80% 이상을 차지한다고 해도 과언이 아닌 전처리 파트의 '핸들'이라고 생각한다.
2-3-1. Matplotlib 한글깨짐 해결
해당 코드는 타 블로그 코드를 발췌했는데, 출처는 아래 블로그이다.
jupyter notebook - 그래프 한글 폰트 설정
주피터 노트북에서 그래프 그릴 때 운영체제에 따라 한글 폰트를 다르게 설정하는 방법 - 한글 깨짐 현상 해결
velog.io
# Matplotlib 한글 깨짐 해결
# 파이썬 시각화 패키지 불러오기
import matplotlib.pyplot as plt
%matplotlib inline
# 사용자 운영체제 확인
import platform
platform.system()
# 운영체제별 한글 폰트 설정
if platform.system() == 'Darwin': # Mac 환경 폰트 설정
plt.rc('font', family='AppleGothic')
elif platform.system() == 'Windows': # Windows 환경 폰트 설정
plt.rc('font', family='Malgun Gothic')
plt.rc('axes', unicode_minus=False) # 마이너스 폰트 설정
2-3-2. Gender 분포
가장 먼저, CustomerID 이후 첫 컬럼인 Gender의 분포를 파이차트로 살펴보았다.
코드 살펴보기
# 성별 분포
target = df['Gender']
ratio = [target.value_counts()['Female'], target.value_counts()['Male']]
labels = target.unique().tolist()
explode = [0.05, 0.05]
colors = ['gold', 'lightgray']
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 2}
plt.pie(ratio, labels=labels, explode=explode,
shadow=True, colors=colors, startangle=260, autopct='%.f',
wedgeprops=wedgeprops);
plt.title("성비 분포");
- ratio : 들어갈 숫자
- labels : ratio별 라벨
- explode : 차트 조각 간 간격
- colors : 차트의 색깔 (색상표 알파벳으로 작성해도 무방)
- wedgeprops : 파이차트를 피자모양 -> 도넛모양으로 바꾸기 위한 설정
- autopct : 표기되는 수치의 표현 방법. %를 붙이거나, 소수점을 조절할 수 있음
- title : 차트의 타이틀
코드 실행 결과

결론: 여성이 44%, 남성이 56%. 남성이 12% 더 많이 분포한다.
2-3-3. Gender에 따른 Age 분포
성별을 살펴봤으니 그 다음 컬럼인 Age를 살펴봤다. 이때, 위에서 남성의 비율이 더 높았으므로, Age 분포에서 Gender 영향도 있을 것 같아, Gender 별 Age 분포를 살펴봤다.
코드 살펴보기
print(df.groupby([df['Gender'],df['Age']]).count())
print('\n----------------------------------\n')
def MakeDF(target, color):
tg_df = pd.DataFrame(df[df['Gender']==target]['Age'].value_counts()).sort_index()
x_labels = tg_df.index
y_labels = tg_df['Age']
plt.plot(x_labels, y_labels, label=target, color=color, alpha=0.9, marker='.')
font = {'color': '#191919',
'size': 15,
'weight': 'bold'}
MakeDF('Male', '#BDBDBD')
MakeDF('Female', '#FFE400')
plt.xlabel('나이', labelpad=15, fontdict=font, loc='center')
plt.ylabel('개수', labelpad=15, fontdict=font)
plt.legend(ncol=1, fontsize=13, shadow=True)
plt.axis([17, 71, 0, 8]) # X, Y축의 범위: [xmin, xmax, ymin, ymax
plt.show()
코드 실행 결과
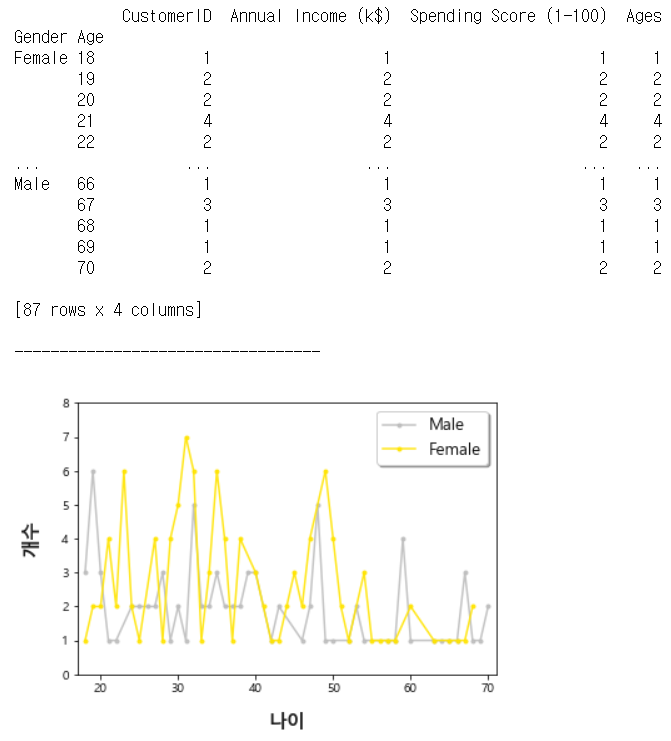
데이터가 200개밖에 되지 않아, 겹치는 연령 자체가 적어 Age를 그대로 사용하여 EDA를 보는 것 보다, 연령대를 나눠 EDA를 보는 것이 옳겠다고 판단했다.
따라서 연령대 별 EDA를 구성해보고자 Ages라는 컬럼을 새로 생성했다.
코드 살펴보기
import math
df['Ages'] = df['Age'].apply(lambda x: math.floor(x*0.1)*10)
df.Ages.head(3)
'데이터 공부 > Python' 카테고리의 다른 글
| 스트리밍 데이터 기반 AI 모델 처리에 대한 고민 (1) 람다 아키텍처 활용 (0) | 2022.09.04 |
|---|---|
| Python Error - most likely due to a circular import 해결 (0) | 2022.04.13 |
| 05. 데이터 시각화 (0) | 2021.06.04 |
| 04. String Manipulation (0) | 2021.06.04 |
| 03. 데이터 셋 병합 (Concat, Merge) (0) | 2021.06.01 |