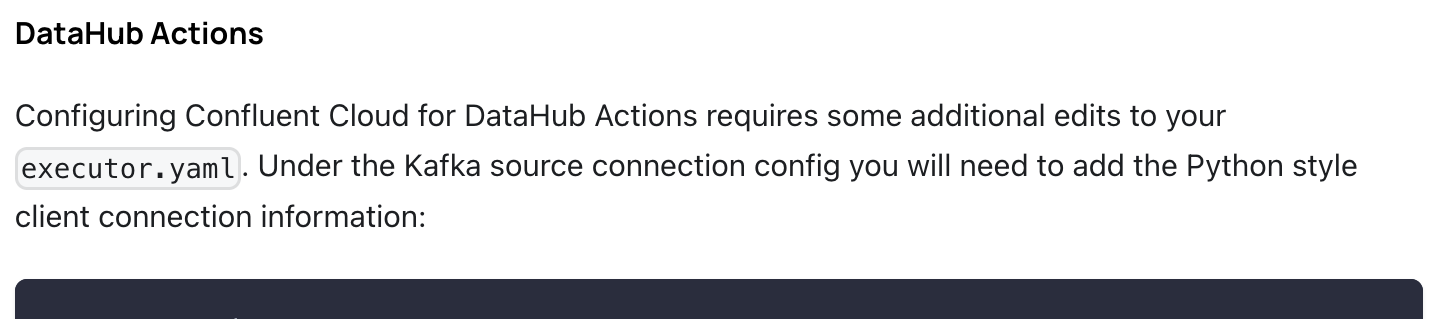
안녕하세요 한소희입니다. 공부를 통해 배운 내용을 작성하고 있습니다. 혹여 해당 포스팅에서 잘못된 부분이 있을 경우, 알려주시면 빠르게 수정 조치하도록 하겠습니다. 감사합니다. 데이터허브 구축기를 작성해 보고자 한다. 목차는 아래와 같으며, 포스팅이 생각보다 길어져서, 몇 개의 글로 나누어 포스팅할 예정이다. 첫 번째 포스팅에서는 데이터허브가 무엇인지 알아보았고 두 번째 포스팅에서는 데이터허브 구축 시 ElasticSearch 구축~연동 과정을 다루었다. 이번 포스팅 또한 두 번째 포스팅에 이어서, 데이터 허브 구축 과정을 포스팅할 생각이다. Confluent Kafka 연동 및 DB 연동, Datahub 구축 과정을 회고하며 포스팅을 마무리할 계획이다. 목차 01. Datahub 02. Datahub ..