지난 4월 12일, 휴대폰을 두고 화장실에 들어갔다가 갇힌 남성의 사연이 화제였다.
살려달라 외쳤지만 나아질 기미가 보이지 않자, 방 안 휴대폰을 떠올렸다고 한다.
그래서 그는, '하이 빅스비'를 외쳤고, 부모님께 통화연결을 해달라는 음성인식에 성공하여 화장실에서 탈출할 수 있었다.
뉴스 출처: https://www.hankyung.com/society/article/2023041213427
이 기사를 접한 뒤, 문득 궁금해졌다.
빅스비는 어떻게 음성을 인식한건지, 그리고 음성 데이터는 어떻게 수집&처리될지 알고 싶어졌다.
그래서 난, 지난 달 지인과의 대화를 통해 알게 된 STT를 떠올렸고, 해당 STT 튜토리얼을 직접 시도해 보았다.
목차
STT의 원리
STT 튜토리얼
한국어 음성인식에 대하여
01. STT의 원리
STT란, Speech to Text의 약어로, '음성 인식'을 뜻한다.
이는 일반적으로, '트레이닝 데이터셋을 녹음' 하고, 이를 벡터화하여 학습시킨다.
이후, 테스트 데이터셋의 데이터 간 변화(특성 벡터)를 추출하여, 쪼개진 특성을 모델과 대조한다.
이 과정을 통해, 가장 일치 확률이 높은 개별 음소에 매칭시키는 과정을 거친다.
이후, 음성인식 결과가 문맥에 맞도록 기존 학습 모델을 기반으로 교정시키는 것이 STT의 큰 원리라고 한다.
그림으로 보면 아래와 같다.

또한 그림으로 정확한 이해가 어렵다면, 아래 링크를 참고해도 좋다.
https://www.youtube.com/watch?v=9h8FxFuOzIc
02. STT 튜토리얼
따라서 해당 작업에 대해, 직접 튜토리얼을 진행해 보기로 했다.
문서는 '장보윤'님께서 번역하신 아래 링크를 참조했다.
https://tutorials.pytorch.kr/intermediate/speech_recognition_pipeline_tutorial.html
Wav2Vec2를 이용해서 음성 인식하기
저자: Moto Hira 번역: 장보윤 이 튜토리얼은 wav2vec 2.0으로 사전 학습된 모델을 이용해서 어떻게 음성 인식을 수행하는지 안내합니다. [ 논문] 개요: 음성인식은 아래와 같은 과정으로 진행됩니다.
tutorials.pytorch.kr
위 링크의 과정을 그림으로 크게 요약하면 아래와 같다.

이렇게, 녹음된 TEST 데이터를 WAV2VEC2 모델에 돌리면, 해당 모델에 근거하여 TEST데이터의 음향 특성을 추출하고 카테고리를 분류해 준다. 이 과정을 거치면, TEST 데이터셋이 어떤 원소로 이루어져 있는지 출력된다. 이를 디코딩하여, 음성 결과값을 텍스트로 변환할 수 있다.
02-1. WEV2VEC2 모델이란
이때, 위 튜토리얼에서 사용하는 WEV2VEC2 모델이란, 2020년에 페이스북에서 발표한 모델로, 53,000시간의 라벨링 없는 데이터로
representation training을 진행한 뒤, 단 10분의 라벨링 데이터로 음성 인식기를 만들어 낸 획기적인 모델이다.
라벨링 없는 데이터로 학습이 가능했던 이유는, 내부 동작원리에 CNN 알고리즘을 사용하여, 자기 학습이 가능했기 때문이라고 한다.

CNN이란, Convolution Neural Network의 약자로 합성곱 신경망 딥러닝 모델을 의미하며, 데이터에서 스스로 패턴을 학습하고 데이터를 분류할 수 있다.
CNN은 스스로가 학습을 하기 때문에, 무수한 라벨링이 부담스러운 영상이나 음성 학습 시 많이 사용된다고 한다.
02-1. 튜토리얼 학습 결과
코드는 튜토리얼 링크와 동일하게 colab에서 진행했고,
I|HAD|THAT|CURIOSITY|BESIDE|
ME|AT|THIS|MOMENT|
라는 결과값을 잘 출력받을 수 있었다.
colab에서 튜토리얼 진행 시 유의사항
런타임 유형 변경 - 하드웨어 가속기 - GPU로 설정해야 한다.
02-2. 튜토리얼 응용 학습 결과
그런데 문득, '테스트 데이터라서 잘 출력된 것이 아닌가' 하는 생각이 들었다.
테스트 데이터가 아닌, 실제 내 목소리로 코드를 돌려도 잘 출력될지 궁금하여, 직접 음성 녹음을 한 wav 파일을 넣고 돌려보았다.

결과적으로, 잘 출력되는 것을 알 수 있었다.
이로써, WAV2VEC2 모델은, 별 다른 파라미터 튜닝을 하지 않아도 잘 인식이 되는 것을 확인했다.
03. 한국어 음성인식에 대하여
이렇게 영어로 작업을 하다 보니, 한국어 오픈소스도 있는지 궁금해졌다.
한국어도, 별 다른 튜닝 없이 잘 돌아갈지 궁금해졌고, 한번 한국어 음성인식 오픈소스 툴킷을 찾아보고, 이를 테스트해 보기로 하였다.
03-1. Kospeech
찾아보니, Kospeech라는 오픈소스 툴킷이 2021년 이후로 생성된 것을 알 수 있었다.
이는 Pytorch 기반의 딥러닝 모델로, 한국어만 지원된다고 한다.
github 링크는 아래와 같다.
https://github.com/sooftware/kospeech
그리고 현재 내가 찾아본 바에 의하면, 한국의 음성인식 오픈소스는 대부분 이 Kospeech를 근간으로 활용하여 개발된 것으로 보였다.
그렇게 개발된 여러 가지의 모델이 있지만, 그중에서도 나는 아래 링크의 소스코드를 참고하여 한국어 음성인식을 테스트했다.
https://github.com/kthworks/Wav2Vec2-Korean
이 코드는, 위에서 앞서 설명한 WAV2VEC2 모델을 근간으로, Kospeech의 transcription 을 활용하여 한국어를 인식할 수 있도록 트레이닝된 모델이라고 한다.
원래 WAV2VEC2 모델은, 한국어 데이터에 대한 학습이 진행되지 않았기에, 해당 모델은 한국어 데이터셋을 이용하여 추가 학습을 진행한 모델이라고 이해했다.
processor = Wav2Vec2Processor.from_pretrained("Taeham/wav2vec2-ksponspeech")
model = Wav2Vec2ForCTC.from_pretrained("Taeham/wav2vec2-ksponspeech").to('cuda')
코드 내부에 위와 같은 코드가 있는데, 이처럼 개발자분께서 프리트레이닝 해주신 모델을 활용하여, 아무런 튜닝을 거치지 않고 코드를 실행시켜 보았다.
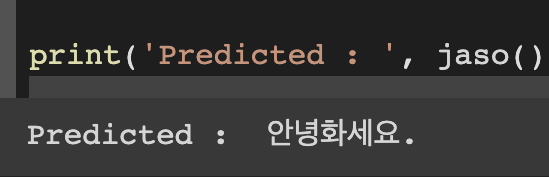
그 결과, '안녕하세요'라는 문구를 '안녕화세요'로, 어느 정도 인식하는 것을 알 수 있었다.
04. 결론
데이터 엔지니어 직무기 때문에 실제 현업에서는 이런 일을 하진 않지만, 그래도 이렇게 간단히라도 다뤄보니 매우 재미가 있었다.
그리고 뎁스 있게 알아보려고 할수록 확실히 난이도가 있었다.
나중에 기회가 된다면, 이러한 일련의 과정들을 딥다이브 해보고 싶다는 생각이 들었다.
더불어, AI의 개발과 발전에 따라 '데이터가 더욱 큰 자산이 되겠구나' 싶었다.
나는 조금씩 성장 단계를 밟고있는 '주니어 데이터 엔지니어' 단계기에, '정확성과 신뢰성을 바탕으로 대용량 데이터의 안정적 수집 & 품질 관리'에 대한 고찰을 자주 해보면 좋을 것 같다고 생각했다.
점점 무수히 많아지는 데이터의 늪(?)에서, 데이터를 신뢰성 있게 활용할 수 있는 환경을 만들기 위해, 더 배우고 성장해야겠다고 느낀 시간이었다.